GPT-3 동작 원리
OpenAI의 GPT-3이 엄청난 언플을 통해 대중들에게 꽤나 핫하다. 국내 유명 경제 팟캐스트에서도 소개가 되었으며, 마치 혼자 글을 청산유수처럼 짓는 것처럼 묘사되었다. GPT-3의 비밀을 파헤쳐보자.
문장을 만들어내는 인공지능에는 아래 움짤처럼 보통 인풋으로 키워드가 좀 들어간다. 이를 바탕으로 글을 쓰기 위해서, 머신러닝 모델이 엄청난 양의 데이터를 '학습한' 것을 바탕으로 아웃풋을 낸다. 예를 들어보자.

즉 인풋으로 '로봇공학의 삼원칙 중 제1원칙을 말하라'를 줬을 때, 이에 맞도록 '로봇은 인간에게 해를 가하거나, 혹은 행동을 하지 않음으로써 인간에게 해가 가도록 해서는 안된다'를 말해야 한다.
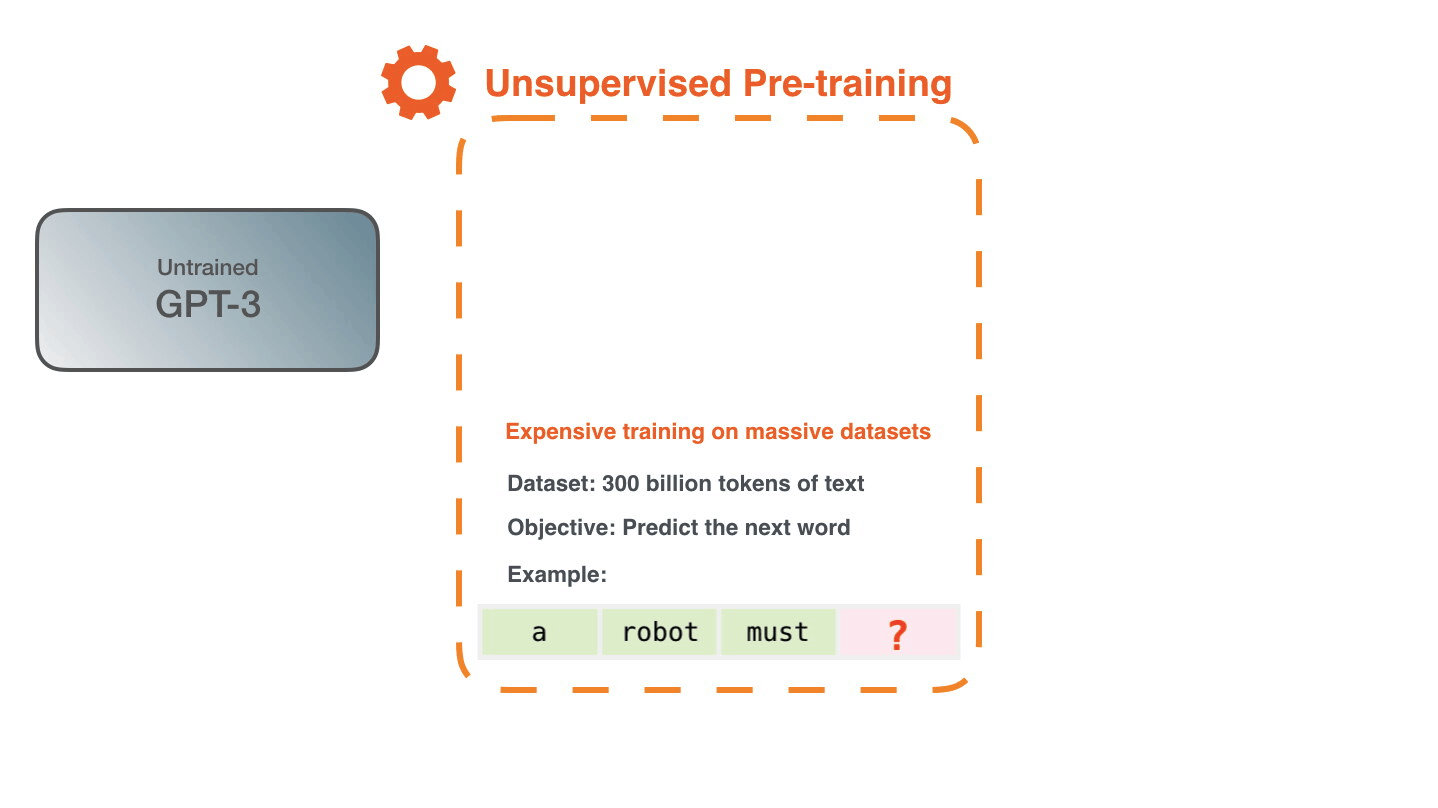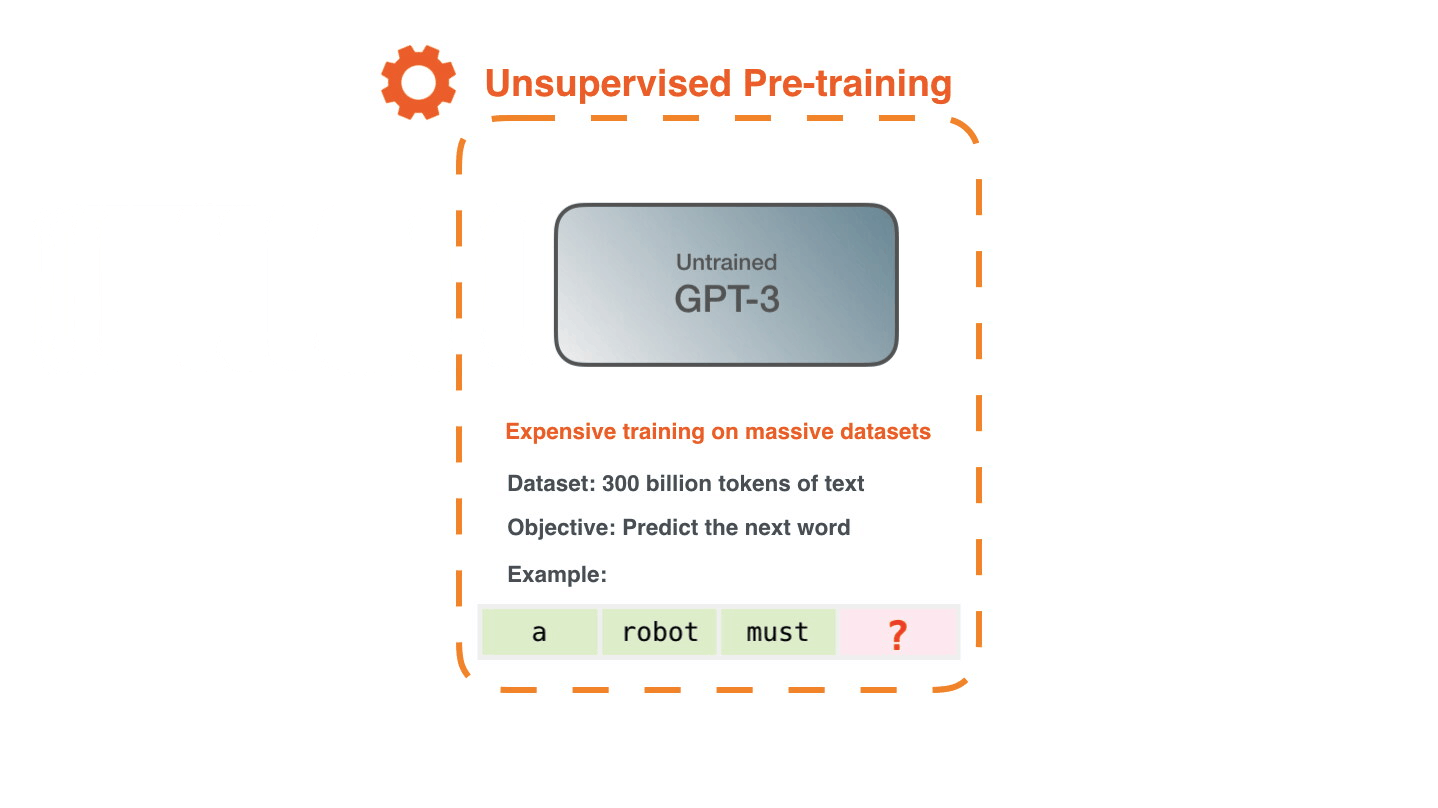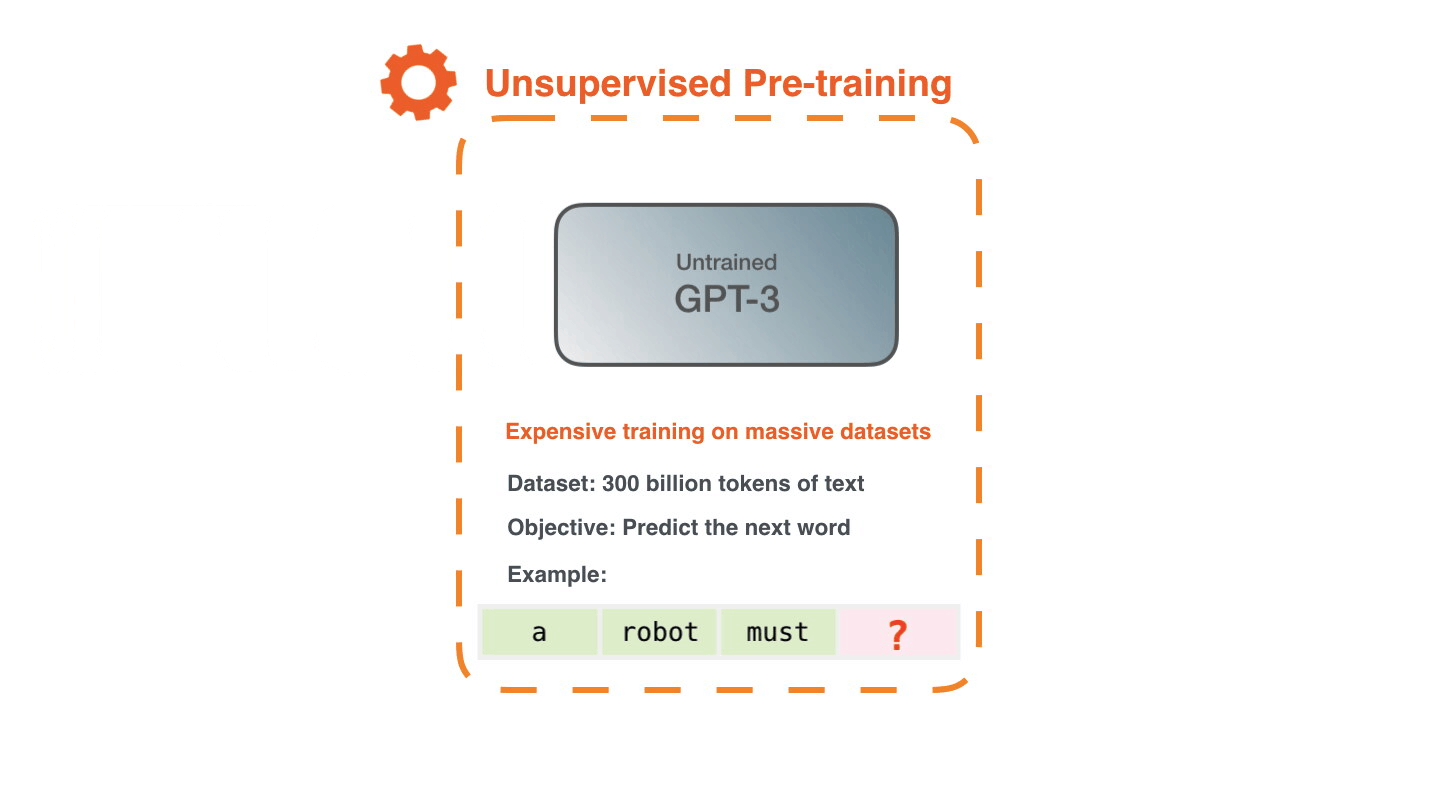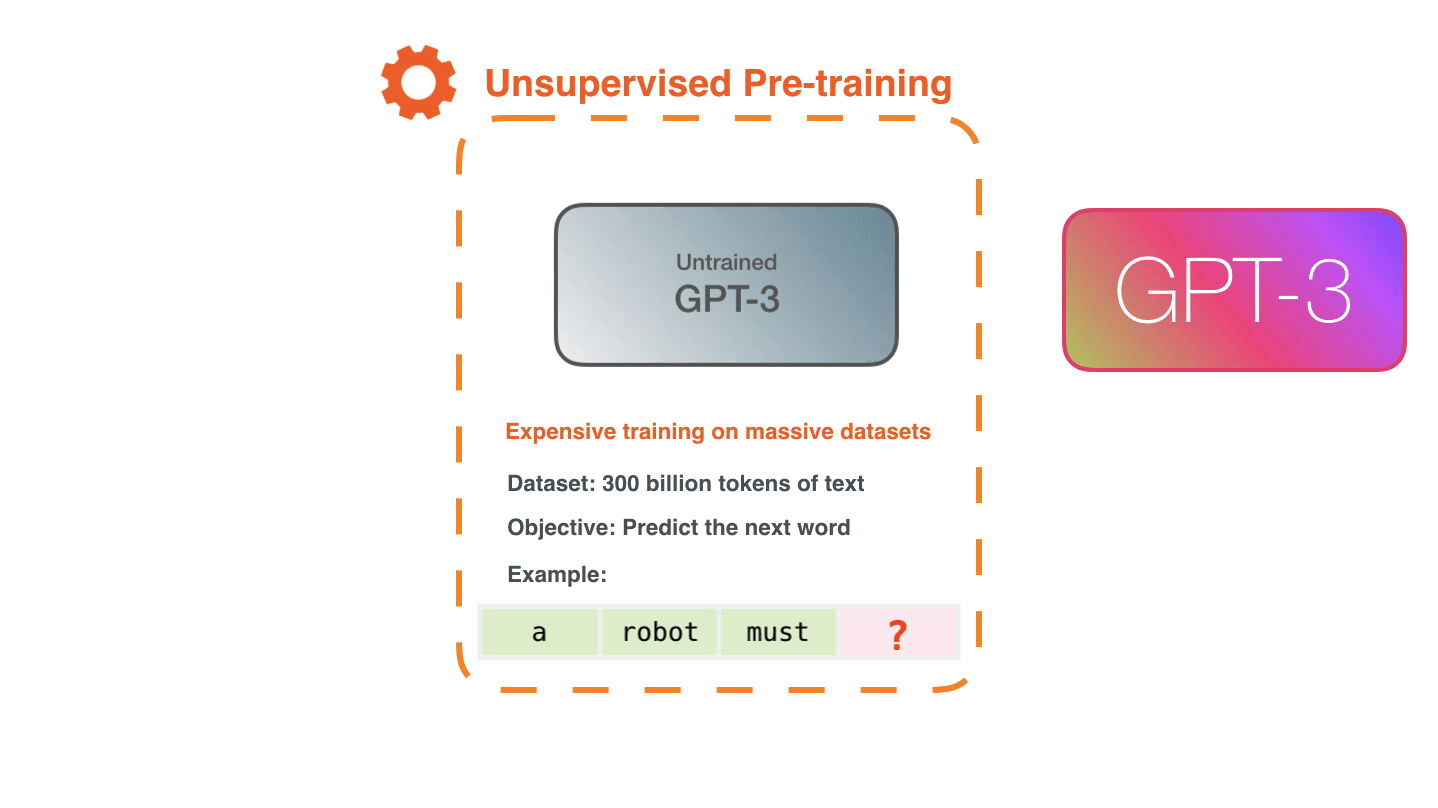
이를 위해 GPT-3은 엄청난 양의 텍스트를 학습했다. 약 3000억개의 텍스트 토큰이 사용되었다. 대략적인 원리를 살펴보자. 아래 그림은 어떤 하나의 문장을 생성하기 위해 필요한 학습자료 예시 중 처음 세 문장이다. 로봇공학의 제2원칙에 대한 문장을 보고, 모든 문장에 대한 examples를 만들어서 학습하는 과정이다.

이 AI 모델이 오직 하는 일이라곤 다음에 올(must 뒤에) 단어를 예측하는 것이다. 본 문장대로 obey란 단어가 나와야하는데, 다른 단어가 나오면 error라 처리한다. 수없이 많은 에러 끝에 언젠가는 obey가 나와서 학습을 하게 된다. 상당히 무식한 방법이다.

즉 엄청난 양의 노가다를 통해 글을 만드는 것이므로, GPT-3이 진짜로 글 짓기 능력이 있다고 생각하지 않는 것이 좋다.
참고: https://jalammar.github.io/how-gpt3-works-visualizations-animations/